- data for OCR/PDF/Survey")
은행명 및 계좌번호는 추출하기도 어려운 구조로 이루어졌으며, 검증하기도 매우 어렵습니다. 그래서 당사의 OCR+에서는 다음과 같은 2가지 방식으로 추출과 검증을 하고 있기에 추출된 은행명 및 계좌번호의 신뢰성이 아주 높다고 할 수 있습니다.
1. 은행명 및 계좌번호의 추출(은행별 계좌번호 패턴화 - userDB를 이용한 패턴 등록)
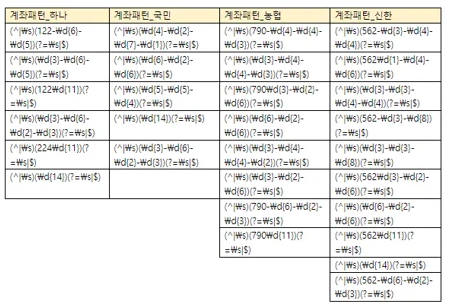
위 패턴은 사용자가 계속 등록하거나 수정할 수 있습니다.
또한, 정규표현식을 사용해서 인터넷을 통해서 쉽게 패턴을 수정할 수 있습니다.
그리고, 은행계좌 번호의 특성상 13자리 패턴이 많기 때문에 가능한 발급기관이 이용하는 점번호 패턴을 이용해서 오류가능성을 처음부터 줄이고 있습니다.(농협의 790, 신한의 562 패턴을 참고하세요)
그럼에도 불구하고 은행명 및 은행계좌번호를 범칙금고지서에 표시하는 방법은 기준이 없기 때문에 패턴을 통한 계좌번호 추출은 그 한계를 가지고 있습니다.
2. 은행명 및 은행 계좌번호의 유효성 검증
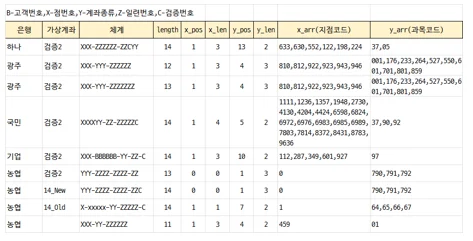
- 은행명 및 계좌번호 체계를 새로 만든 테이블의 일부자료
- 약 3년간 범칙금 고지서 1백만건을 분석해서 만든 은행 계좌번호 분석자료
위 계좌번호 검증 테이블을 기반으로 2차 확인에 들어가서, 확정된 계좌번호가 아닌경우 별도로 표시해서 사용자가 검증할 수 있도록 합니다.
즉, OCR+는 은행계좌번호 패턴을 가지고 1차 계좌번호를 추출하고, 2차 계좌번호 중 과목코드와 점번호를 기반으로 검증하여 사용자가 확신하고 사용할 수 있는 자료를 추출합니다.
사실, 과거부터 존재하던 금융기관은 금감원에 점번호와 과목코드를 등록 관리하고 있으나, 최근에 인가된 인터넷 뱅크(카카오뱅크, 케이뱅크)는 점번호가 없습니다. 지점없이 은행 영업을 하고 있기 때문에 위에서 사용하고 있는 점번호 + 과목코드 검증도 완벽하지는 않습니다. 이런 방대한 자료로 검증을 했다고 하더라도 OCR 결과물은 100% 완벽할 수 없습니다. 하지만, 이런 검증 조차도 하지 않고, 그냥 OCR엔진에서 읽어준 자료를 사용자에게 보여준다면 OCR은 현재와 같이 그럴싸해 보이는 장난감이지, 업무용으로 사용할 수 없는 수준일 수 밖에 없습니다.
제가 알고 있는 한, 현재까지 개발된 대부분의 OCR은 아주 비싼 장남감에 불과합니다. 단지, 자동차번호판을 인식하고, 주민등록증의 주민번호를 인식하는 단순한 업무에 활용할 수 밖에 없는 초보적이고 단순업무에만 사용되고 있기 때문입니다.
OCR로 이미지를 텍스트로 99% 전환했다고 해서, 실무에 사용할 수 없기 때문입니다. 1%가 어디 있는지 모른다면 99% + 1%를 사람이 검증하여야만 사용할 수 있는 데이터가 되기 때문입니다. 만약에 99% 일치된 곳과 1% 잘못된 곳을 표시해 준다면 가장 완벽한 OCR엔진이 되겠지만, 이건 불가능 합니다. 왜냐하며 1%가 잘못된 곳이라는 것을 알고 있는 엔진이라면 이미 수정해서 100% 완벽하게 변환된 텍스트를 보내주게 됩니다.
OCR엔진의 오류가 아니더라도 OCR판독은 오류가 날 수 밖에 없습니다. 예를 들면 범칙금을 뜯을때 글자 부분도 뜯겨나가면, 아무리 훌륭한 OCR엔진이더라도 읽을 수 없습니다. 2중으로 인쇄된 경우도 마찬가지 입니다. 접힌 부분이 이미지로 전환되면 줄선을 만들고 그 줄선은 OCR엔진에 혼란을 줍니다. 심지어 사람 조차도 판단하기 어려운 사례도 많이 있기에, 100% 완벽한 OCR엔진을 기대할 수 없습니다. 그래서 어디가 문제가 되는지 알 수 있는 로직이 탑재된 OCR+의 기능이 꼭 필요한 이유입니다.
감사합니다.