 - data for OCR/PDF/Survey")
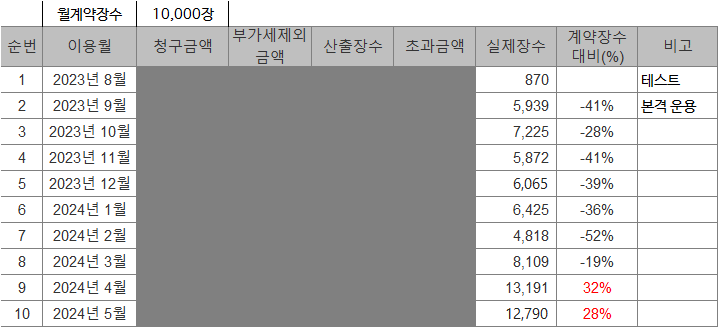
(H사에서 운영중인 OCR+의 월별 데이터 사용내역)
위 표에서 보다시피 당사에서 개발해서 H사에서 매일 사용중인 OCR+는 당사와 최고 계약 장수, 월별 1만장을 초과하고 있습니다. 바로 이점이 실무자들에게 OCR+가 유용하다는 증빙입니다.
최초 계약장수 1만장도 평균 작업량 6천장 대비 충분히 넉넉하게 계상한 숫자입니다. 그럼에도 2024.5월 현재 30%를 초과해서 OCR+를 사용하고 있습니다. 당사 OCR+를 이용해서 데이터를 추출하는 경우 장당 135원 수준이고, OCR업계 관행상 과태료 OCR 데이터 추출은 장당 1천원 ~ 1천5백원 수준입니다. 이, H사의 경우 장당 865원 이익을 받는다고 한다면, 2024.5월에만 약 1천1백만원의 프로그램 사용이익을 보고 있습니다.
이에 반해서, OCR+프로그램의 성공과 달리 일반적인 OCR 프로그램을 개발하기 위한 절차는 다음과 같습니다.
단순하고 정형화된 업무인데, 사람이 직접하면서 발생하는 불편함을 인식하고 그 해결책을 찾는다. 자동차 과태료 데이터 추출은 각종 지자체에서 발행하는 자동차 과태료 용지는 200여개가 넘기는 하지만, 추출하고자 하는 데이터는 차량번호, 전자납부번호, 사고일시, 사고장소, 사고내용, 납기일, 납부금액, 은행계좌번호 등 10여개에 불과하다. 대부분의 대규모 리스회사 또는 캐피탈회사에서는 수만대를 보유하고 있는 자동차의 과태료 통지업무를 대행하고 있기 때문에 자동차 과태료 용지로 부터 정확한 데이터를 추출하고, 실제 운전자에게 범칙금을 납부하도록 한다. 단순 범칙금 납부 뿐 아니라, 이의제기가 필요한 경우에도 실제 운전자의 도움이 필요하기 때문에 빠르고 정확한 데이터의 전달이 필수 사항이다.
리스사 또는 캐피탈사에서 실제 운전자에게 통지하고자 하는 데이터는 정확해야 한다. 물론 통지서 이미지를 사용자에게 전달하기도 하나, 데이터 관리 또는 문자 메시지 발송을 위해서는 정확한 데이터 추출이 선행되어야 한다.
따라서 OCR회사에게 견적을 받아보고 그 해결책을 요청한다. 규모가 작은 회사인 경우 프로그램 개발비가 보통 억단위 이기 때문에 프로그램 개발보다는 아르바이트를 이용해서 키보드로 각종 정보를 직접 엑셀에 투입하는 방식을 유지한다. 이때 문제가 발생한다. 과태료 고지서에 나와 있는 각종 정보를 사람이 직접 투입하는 경우에는 에러가 발생하고, 이 에러를 발견하게 되면 추적하고 수정하는 일과가 추가된다. 당연히 불이익을 받은 고객의 불만도 높아진다.
아르바이트로 투입한 정보가 불완전함에 따라 다시 OCR업계에 문의하고 프로그램 개발을 시작한다. OCR회사에서는 복잡한 시스템과 자기네 회사가 얼마나 정확한 이미지 추출을 하는지를 전문용어로 설명하기 때문에 사용자측에서는 믿고 기다린다. 6개월 후에 프로그램이 완성되면 기존 직원들의 업무분장을 다시할 부푼꿈을 꾸기도 한다.
프로그램 개발 착수와 동시에 실무부서에 각종 데이터를 요구하고 샘플 고지서를 요청한다. 2~3개월 후 1차 버전을 경영자와 실무자에게 시연하고 2~3개월 후에는 사람 개입이 없을 정도의 완벽한 데이터 추출이 될 것이라는 약속을 한다. 단, 이 과정에서 빠른 속도와 정확도를 높이기 위해서 전문 시스템 도입이 필요함을 강조한다. PC수준에서 전문적인 프로그램을 OCR프로그램을 돌리기는 한계가 있고, 데이터 보호를 위해서 약 1억원 정도의 전문 시스템을 구축할 것을 권장한다. 사용자 측에서는 OCR속성을 잘 모르기 때문에 전문가의 의견을 믿고 추가 투자하기로 결정한다. 그들은 한번 더 프로그램 완성되기를 기대한다.
프로그램 개발기한이 6개월이라고 하면 6개월이 넘도록 완성된 프로그램을 보여주지 못한다. 프로그램 개발사에서는 마지막 점검중이며 완성도를 높이기 위한 작업이라고 한다. 시스템 설치를 위한 시간과 적합성 테스트를 위한 시간이 필요해서 약간 늦어지는 것 뿐이라고 설명한다. 프로그램 개발업체에서는 사용자측과 협의하여 최종 시연회를 준비한다. 사용자 측에서는 비록 비용도 많이 들고 개발기간도 늦어졌지만 최종시연회에서 본 프로그램의 미려함과 데이터 추출에 만족한다. 경영진은 실무자들에게 새로운 시스템을 적극 이용해서 효율을 높일 수 있도록 권장한다.
실무 사용자들은 만족하는 편이다. 왜냐하면 그들이 손으로 했던 모든 업무 중 80% ~ 90%의 데이터를 자동으로 뿌려주고, 나머지 10% ~ 20%만 과거 방식으로 타이핑하면 되기 때문이다. 그런데도 불구하고 인력 감소 효과는 없다. 경영진에서는 왜 거액을 들여 새로운 시스템을 구축했는데도 불구하고 인원을 축소해서 다른 업무에 배치할 수 없는지를 점검한다. 인원 축소가 안되는 이유는 10% ~20%의 데이터를 찾는 방법은 시스템 개발 이전과 같이 과태료 용지 100% 전체에서 찾아야 하기 때문이다. 물론 실무자들은 그 위치를 이미 알고 있기 때문에 다소 작업시간 감소에 도움이 되고 있기는 하다. 단, 전자납부번호 19자리 즉, 1234567890123456789라는 숫자에서 에러가 발생한 경우 실물과 대조해서 사람 눈으로 한개한개 확인하는 과장은 차라리 사람이 직접 타이핑 하는 방식이 더 효율적이라는 사실도 알게된다.
시간 절약이라는 목표를 달성하지 못함에도 불구하고 예전보다는 정확한 데이터 추출과 검증이 이루어지고 있다는 점에서 스스로 만족한다.
실무자들은 과거 방식으로 모두 회귀한다. 즉, 10% 에러를 찾는 시간에 차라리 직접 타이핑하는 방식이 시간이 절약되기 때문이다. 실무자들은 일이 빨리 끝나야 퇴근을 할 수 있기 때문에 프로그램 개발사에서 주장하는 거창한 프로그램의 효용을 믿지 않는다. 실무자들은 불만이다. 그 전에는 과태료 용지만 보고 엑셀에 투입하면 끝나는 일을, 이제는 봉지를 이쁘게 뜯어서 스캔하고, 스캔 파일이름을 정리하고, 그 이미지에 맞는 데이터를 수기로 다시 입력해야 하는 불편만 있기 때문이다. 하지만 경영자들에게 이런 사실을 보고하지 않는다. 실무자 또한 프로그램 개발이 되기를 주장하던 사람들이었기 때문이다.
위에 기술한 OCR 프로그램 개발과정은 과장이 다소 섞여 있을지 몰라도 100% 현실을 반영해서 작성된 내용입니다. 프로그램의 산출물은 최초 기대와 다른 것이 일반적이기도 합니다. 보고에 따르면 프로그램 개발후 실패하는 확률이 70%라고 합니다. 제 사적인 견해에 따르면 적어도 50%의 프로그램 개발은 실패라고 볼 수 있습니다. 왜 제가 이런 것을 알 수 있냐면, 금융권은 프로그램을 개발할 때 마다 자체 서버를 별도로 운영하는 방식입니다. 메인 서버는 절대 건들지 않고 문제가 생겨도 프로그램 단위로 에러가 발생해야 하기 때문입니다. 그래서 서버 숫자는 프로그램 개발 횟수와 거의 일치합니다. 제가 근무하던 회사는 전산실에 약 500개의 서버가 있고, 그 중에 반이 최근 1년 동안 데이터 입.출이 없이 가동되는 멍텅구리 서버로 전기만 먹습니다. 항온, 항습, 지진방지, 서버실 진입 방화벽 2개 등 엄청난 시설이 있는 곳에서 꿈을 품고 개발하고 사용하지 않는 서버가 50% 정도로 추산됩니다.
OCR+를 사용해서 자동차 과태료 데이터 추출이라는 난관을 극복하세요. 실무자들의 경험이 바로 OCR+의 우수성을 대변합니다.
감사합니다.

찐 실무에 도움이 되는 소프트웨어이네요. 자료를 보니 더 신뢰가 가네요.